8 Lesson 2: General Tools for Open Science
8.2 Overview
This lesson introduces you to the commonly used tools in open science. It starts out by providing a brief introduction to open science tools and describes persistent identifiers - one of the most common open science tools in use that ensures reproducibility, accessibility, and recognition of scientific products. This is followed by descriptions of other common open science tools that are applicable regardless of your field of study. The lesson wraps up with a description of open science and data management plans that is a key component to sharing your science throughout the research process.
8.3 Learning Objectives
After completing this lesson, you should be able to:
- Recall the definition of open science tools.
- Describe what a persistent identifier is and state an example.
- List a few commonly used open science tools that support research.
- List the components of an Open Science and Data Management Plan and what they include.
8.4 Introduction to Open Science Tools
The word “tools” refers to any type of resource or instrument that can be used to support your research. In this sense, tools can be a collection of useful resources that you might consult during your research, software that you could use to create and manage your data, or even human infrastructure such as a community network that you join to get more guidance and support on specific matters.
In this context, open science tools are any tools that enable and facilitate openness in research, and support responsible open science practices. It is important to note that open science tools are often open source and/or free to use, but not always.
Open science tools can be used for: - Discovery - Tools for finding content to use in your research. - Analysis - Tools to process your research output, e.g. tools for data analysis and visualization. - Writing - Tools to produce content, such as Data Management Plans, presentations, and preprints. - Publications - Tools to use for sharing and/or archiving research. - Outreach - Tools to promote your research.
In this lesson, we introduce you to some of the most general open science tools such as persistent identifiers, metadata, documentation, and open science and data management plans. Regardless of the field of study, these tools and practices are some of the things that you will encounter as you use, make, or share your research. Read more about open science tools on OpenSciency.
8.5 Persistent Identifiers
A digital persistent identifier (or “PID”) is a “long-lasting reference to a digital resource” that is machine-readable and uniquely points to a digital entity, according to ORCID examples of persistent identifiers used in science are described below.
8.5.1 ORCID

An “Open Researcher and Contributor Identifier” (ORCID) provides valid information about a person. Following are some key details about ORCIDs.
A free, nonproprietary numeric code that is:
- Uniquely and persistently identifies authors and contributors of scholarly communication.
- Similar to tax ID numbers for tax purposes.
ORCIDs are used to link Used to link researchers to their research and research-related outputs. It is a 16-digit number that uniquely identifies researchers and is integrated with certain organizations (like some publishers) that will add research products (such as a published paper) to an individual’s ORCID profile. ORCIDs are meant to last throughout ones career, and helps to avoid confusion when information about a researcher changes over time (e.g. career change or name change). (cite: https://orcid.org/)
Many publishers, academic institutes, and government bodies support ORCID. In 2023, ORCID reported over 1,300 member organizations and over 9 million yearly live accounts. You can connect it with your professional information (affiliations, grants, publications, peer review, and more).
8.5.2 Digital Object Identifiers (DOI)
A DOI is a persistent identifier used to cite data, software, journal articles, and other types of media (including presentation slides, blog posts, videos, logos, etc.).
Unlike dynamic transient URLs, DOIs are static pointers to documents on the internet. Since a DOI is static, each new version of data or software that you want to cite will need a new DOI. Some DOI providers allow for one DOI to point to “all versions” and a series of individual DOIs for each specific version. Individuals cannot typically request a DOI themselves, but rather have to go through an authorized organization that can submit the request.
Making a DOI for your product ensures its longevity! This means, if you cite a DOI in a research paper, you can be confident that future readers will be able to follow that citation to its source, even if websites have completely changed in the meantime.
For example, the DOI: 10.5067/TERRA-AQUA/CERES/EBAF-TOA_L3B004.1 will always resolve to a web page that explains what the CERES_EBAF-TOA_Edition4.1 data set is and how to download it. (See the screenshot below if you’re curious what this dataset actually is!)
DOIs are provided and maintained by the International Organization for Standardization (I SO): https://www.doi.org/.

8.5.3 Citations Using DOIs
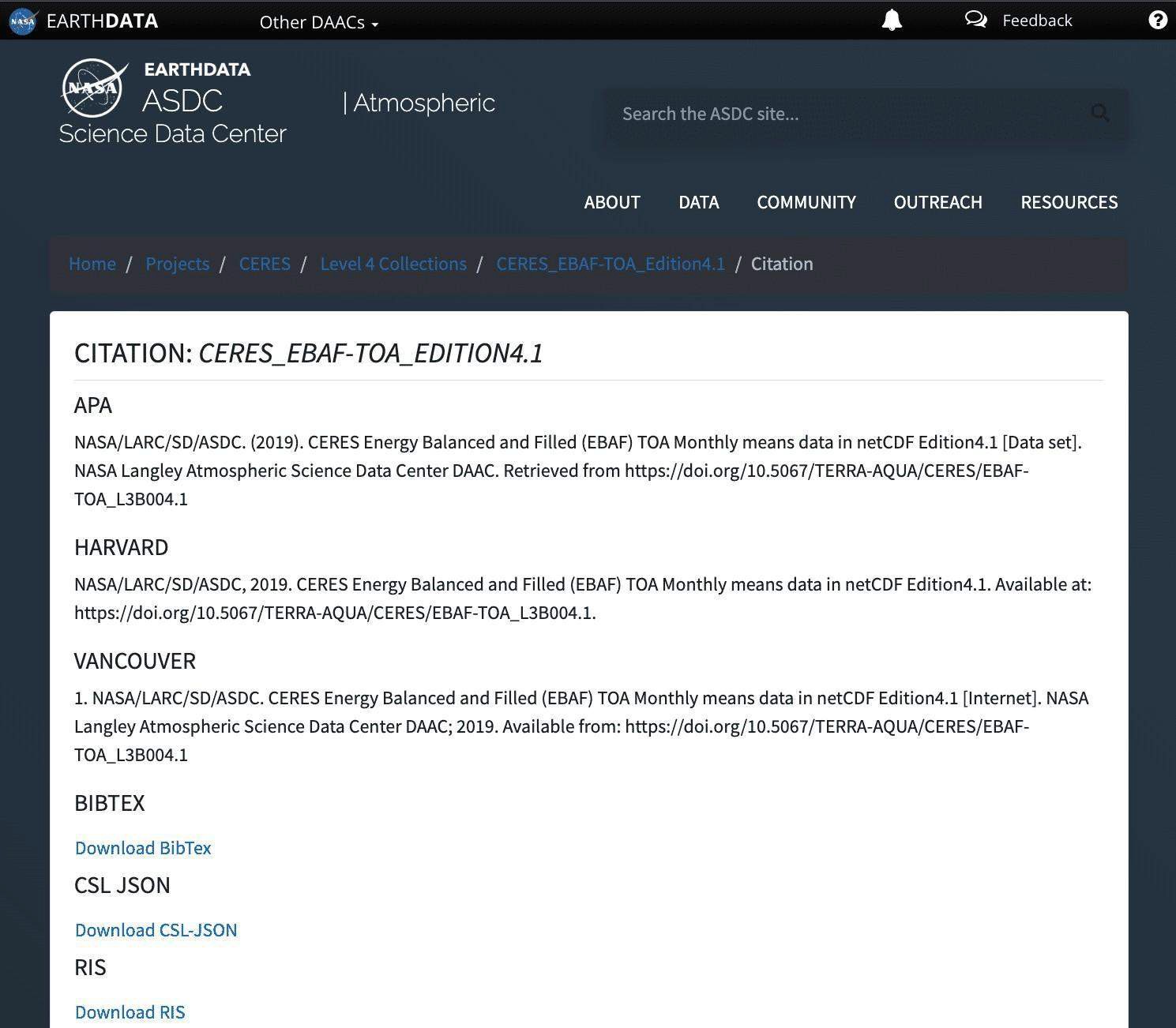
DOIs make citing research products easier and more useful.
Data repositories will typically instruct you on the exact way to cite their data, which includes the correct DOI. For example, let’s take a look at the CERES_EBAF-TOA_Edition4.1 data set mentioned above. This is an example from the Atmospheric Science Data Center’s (ASDC) website.
8.5.4 Activity 2.1: Find and Resolve a DOI
In this activity, you will search for a DOI for a data set or piece of software that you use, and you will then use the DOI website to “resolve” the DOI name. By “resolving”, this means that you will be taken to the information about the product designated by that particular DOI.
- Find the DOI for a dataset or software you use often.
- This should be listed either in the citation file, or in the website where that data/software is published.
- If you can’t find a DOI, you can instead locate the DOI listed on this page: https://asdc.larc.nasa.gov/project/CERES/CERES_EBAF-TOA_Edition4.1
- Go to https://www.doi.org/ and scroll down to the bottom of the page to “TRY RESOLVING A DOI NAME”.
- Copy and paste the DOI you found into the form called “TRY RESOLVING A DOI NAME”.
- Click Submit.
- The page should automatically redirect you to a page that explains and contains the cited data.
Activity Takeaways: Find and Resolve a DOI
This activity will vary depending on which DOI you choose to use. However, if you used the example presented, you should find the DOI: 10.5067/TERRA-AQUA/CERES/EBAF-TOA_L3B004.1
And after step 5, you should end up back on the page https://asdc.larc.nasa.gov/project/CERES/CERES_EBAF-TOA_Edition4.1
This is how easy it should be for your readers to find and use your citation information.
8.5.5 Examples of PIDs in Action

| Example 1 ☑ | Example 2 | Example 3 |
|---|---|---|
|
The necessity for a persistent identifier (PID) begins when a researcher writes code. To make the code searchable, the researcher uploads their code to a repository and registers a DOI for their script. Now others can review and use the code, and cite it properly. |
||
| Example 1 | Example 2 ☑ | Example 3 |
|---|---|---|
|
A workshop planning committee collaboratively authors a paper that summarizes the results of a workshop. They collect the ORCIDs of everyone who participated in the workshop, and include them in the paper. Finally, they publish in an academic journal that automatically assigns the paper a DOI. |
||
| Example 1 | Example 2 | Example 3 ☑ |
|---|---|---|
|
A community scientist attends an online conference and gives a short talk. They deposit their slides in an online repository, then create a DOI to enable easy sharing with colleagues and straightforward citation. |
||
8.6 Useful Open Science Tools
8.6.1 Metadata
Metadata are data that describe your data, either accompanying your data as a separate file or embedded in your data file. They are often used to provide a standard set of general information about a dataset (e.g., data temporal/spatial coverage or data provider information) to enable easy use and interpretation of the data.
Metadata is essential to the implementation of FAIR Principles because it makes data searchable in an archive, provides context for future use, and presents a standard vocabulary.
Metadata can be more readily shared than data - it usually does not contain restricted information and it is much smaller than the entire data set.
8.6.2 Purpose of Metadata
Metadata can facilitate the assessment of dataset quality and data sharing by answering key questions, such as information about:
- How data were collected and processed.
- What variables/parameters are included in the dataset.
- What variables are and what variables are related to.
- Who collected the data (science team, organization, etc.).
- How and where to find the data (e.g., DOI).
- How to cite the data.
- Which spatio-temporal region/time the data covers.
- Any legal, guideline, or standard information about the data.
Metadata enhances searchability and findability of the data by potentially allowing other machines to read and interpret datasets.
According to The University of Pittsburgh, “A metadata standard is a high level document which establishes a common way of structuring and understanding data, and includes principles and implementation issues for utilizing the standard.”
Many standards exist for metadata fields and structures to describe general data information. It is a best practice to use a standard that is commonly used in your domain, when applicable, or that is requested by your data repository. Examples of metadata standards for different domains include:
8.6.3 Types of Metadata
There are different types/categories of metadata addressing different purposes:
| Descriptive Metadata ☑ | Structural Metadata | Administrative Metadata |
|---|---|---|
|
Descriptive metadata can contain information about the context and content of your data, such as variable definition, data limitation, measurement/ sampling description, abstract, title, and subject keywords. |
||
| Descriptive Metadata | Structural Metadata ☑ | Administrative Metadata |
|---|---|---|
|
Structural metadata are used to describe the structure of the data (e.g., file format, the dataset hierarchy, and dimensions). |
||
| Descriptive Metadata | Structural Metadata | Administrative Metadata ☑ |
|---|---|---|
|
Administrative metadata explains the information used to manage the data (e.g., when and how it was created, which software and the version of the software used in data creation). |
||
8.6.4 Documentation
Documenting the production and management of your science benefits both you and those that might use your data, code, or results in the future. You are your own best collaborator. Documentation can save you from a headache should you need to reference or reuse your work in six months or attempt to recall meticulous details about your process later on. Properly documented research products increase their usability.
Types of documentation include (many of which will be expanded upon later in this curriculum):
| Data ☑ | Software | Results |
|---|---|---|
|
Summary of the data (e.g., as a README file or user guide) that answers questions such as:
Associated publications – how did others use these data? |
||
| Data | Software ☑ | Results |
|---|---|---|
|
README files: Basic installation and usage instructions. Inline comments in code: Annotations on code components. Release notes: What is new in this version? Associated publications: How did others use this software? |
||
| Data | Software | Results ☑ |
|---|---|---|
|
Associated publications: What was the research process? Packages of data and software for regenerating results. |
||
8.6.5 Repositories
Repositories are storage locations for data, results, code and compiled software, providing the most common way to share and find each of these components. In general, you want to use a long term repository that will independently host and store your data making sure that it is both shared and preserved. Different kinds of repositories serve different purposes. For example, Zenodo acts as an archiving repository for individual version releases of data, software, and publications.
Different types of repositories:
- General repositories
- Domain-specific repositories
- Institutional repositories
- National repositories
Users should select repositories based on their needs. See the lessons in the rest of this module and Modules 3-5 for more details.
8.6.6 Pre-registration
Pre-registration is the process by which a researcher documents their research plans in an open access format prior to the start of a project. This provides a locked, time-stamped proof of the origin of a concept. Pre-registration is currently more widely adopted by certain disciplines, particularly the social sciences.
Types of Pre-Registration Include:
| Standard Pre-registration ☑ | Registered Reports | Registered Replication Report | Sharing Grant Proposals |
|---|---|---|---|
|
An investigator documents their plans in writing and submits them to a pre-registration service. This documents the researcher’s plans prior to undertaking the research, and provides investigators and reviewers with a way to distinguish a priori hypotheses from post-hoc exploratory analyses. The document may be kept private for some period of time, but is usually made public upon submission of the manuscript for publication. |
|||
| Standard Pre-registration | Registered Reports ☑ | Registered Replication Report | Sharing Grant Proposals |
|---|---|---|---|
|
An investigator writes a manuscript describing the motivation for a study and a detailed description of the methods, and submits it to a journal for peer review prior to undertaking the research. The manuscript is reviewed based on the importance of the research question and the quality of the methods. If accepted, the journal agrees to publish the paper regardless of the results, assuming that there are no problems with the implementation of the methods. |
|||
| Standard Pre-registration | Registered Reports | Registered Replication Report ☑ | Sharing Grant Proposals |
|---|---|---|---|
|
A type of registered report in which the investigators wish to attempt to replicate a particular published finding, usually involving multiple research sites. |
|||
| Standard Pre-registration | Registered Reports | Registered Replication Report | Sharing Grant Proposals ☑ |
|---|---|---|---|
|
Another way to document and timestamp research plans and concepts is to share funded grant proposals publicly. This has the added benefit of making the funding process more transparent, and providing examples of successful grant proposals for other researchers, particularly those in their early career stage. |
|||
8.6.7 Why is Pre-Registration Important?
- It forces the researcher to plan and think through both why and how they are pursuing their research question.
- It provides the researcher with a way to determine whether a hypothesis was truly held a priori, versus relying upon memory.
- It forces the researcher to think through their analysis plan in more detail, potentially surfacing issues that could influence the design of the study.
- It helps prevent unethical manipulation of data analyses and project design to yield statistically relevant results.
- Helps prevent selective reporting of measures.
8.6.8 When Can/Should One Pre-Register Their Research?
A planned research activity can be pre-registered at any point, as long as the particular activity being registered has not started. However, there are several points at which registration is most common:
- Prior to the collection of data for a project
- Prior to analysis of an existing or openly available dataset
Source: Registration — Stanford Psychology Guide to Doing Open Science (poldrack.github.io)
A 2023 Nature survey on researcher attitudes towards open science practices found that about 88% of respondents favor sharing data or code online while only 58% support pre-registration. This moderate support for pre-registration among respondents suggests that awareness of its benefits and lingering concerns remain issues. In the next section, we introduce a method to strategize how to best implement open science from the beginning of a study to its end.
8.7 Open Science and Data Management Plans
To successfully use, make, and share science openly, we need an open science and data management plan (OSDMP).
- From day 1, establish a plan for management, preservation, and release of data, software, and results.
- This plan is your blueprint for open science - refer to your plan often to ensure you succeed in your goal of openness.
We’ll discuss each component (data, software, & results) when we cover each topic.
8.7.1 Design Your Science to be Open
Funding organizations and agencies around the world are beginning to require open science plans.
The OSDMP describes how the scientific information that will be produced from scientific activities will be managed and made openly available. Specifically, a plan should include sections on data management, software management, and publication sharing. If your study has other types of outputs, such as physical samples, hardware, or anything else, you should include those in the plan. An OSDMP helps researchers think about the details of how they plan to share results.
A well written OSDMP can help you win funding because it demonstrates your skills at doing open science!
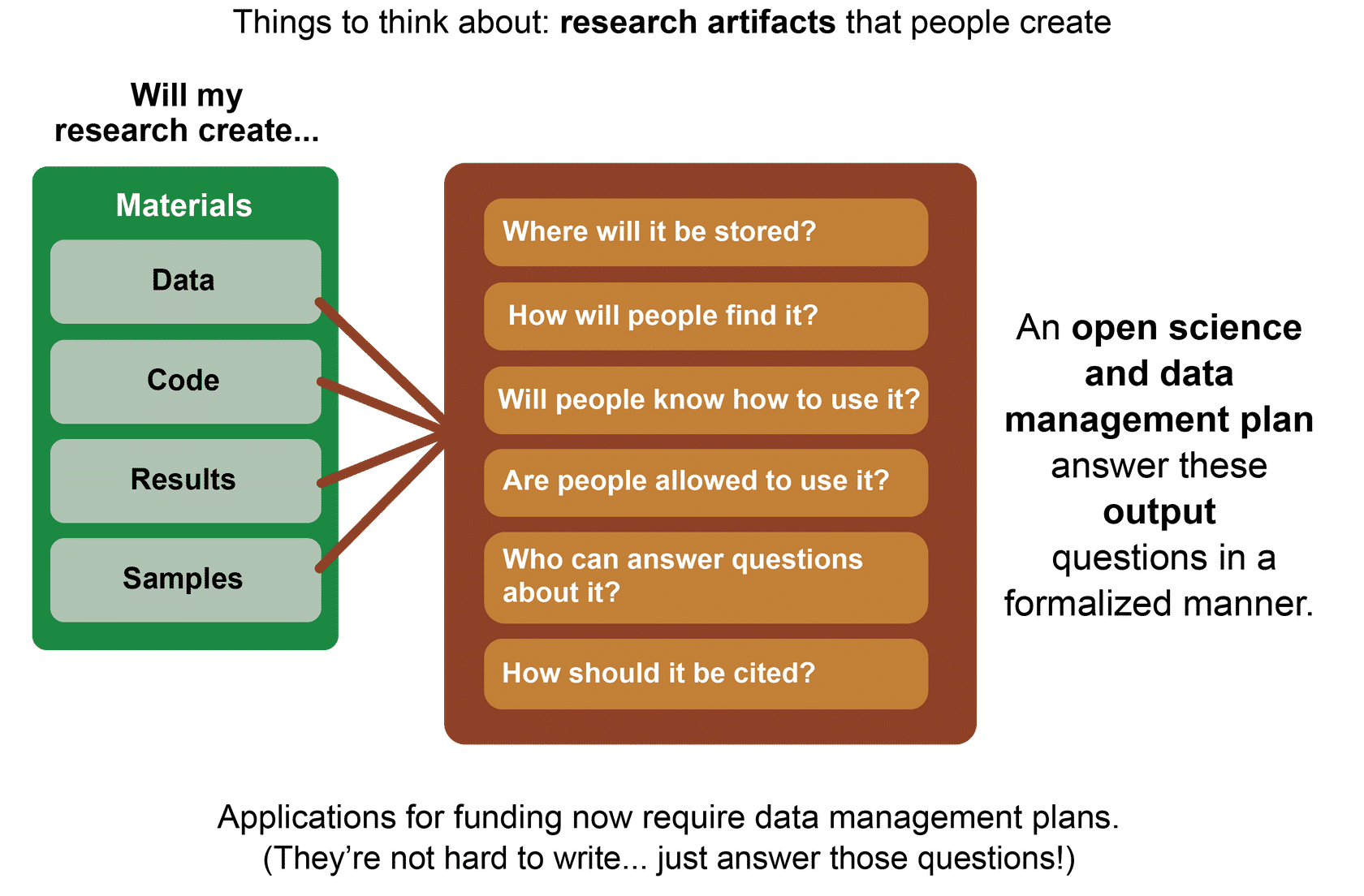
Example sections to include in an OSDMP:
- Data Management Plan (DMP)
- Software Management Plan (SMP)
- Publication sharing
- Other open science activities
- Roles and responsibilities
The steps for each of these sections should include:
- What?
- Description of types of materials that will be produced
- When?
- The schedule for archiving and sharing
- Where?
- The repository(ies) and archives that will be used to share materials
- How?
- The details of how to enable reuse of materials (eg. licensing, documentation, metadata)
- Who?
- Roles and responsibilities of the team members
8.7.2 Data Management Plan
Every major research foundation and federal government agency now requires scientists to file a data management plan (DMP) along with their proposed research plan. Data and other elements such as code and publications have their own lifecycle and workflow, which need to be in the plan. DMPs are a critical aspect of open science and help keep other researchers informed and on track throughout the data management lifecycle.
DMPs that are successful typically include a clear terminology about FAIR and CARE principles and how they will be applied.
The data management lifecycle is typically circular. Research data are valuable and reusable long after the project’s financial support ends. Data reuse can extend beyond our own lifetimes. Therefore, when designing a project or supporting an existing corpus of data, we need to remain cognizant of what happens to the data after our own research interaction ends.
Data management plans typically include the following:
- Descriptions of the data expected to be produced from the proposed activities, including types of data to be produced, the approximate amount of each data type expected, the machine-readable format of the data, data file format, and any applicable standards for the data or associated metadata.
- The repository (or repositories) that will be used to archive data and metadata arising from the activities and the schedule for making data publicly available.
- Description of data types that are subject to relevant laws, regulations, or policies that exclude them from data sharing requirements.
- Roles and responsibilities of project personnel who will ensure implementation of the data management plans.
8.7.3 Software Management Plan
Software management plans describe how software will be managed, preserved, and released as part of the scientific process. This helps ensure transparency and reproducibility in the scientific process. Module 4 on Open Code shares more details about the importance of sharing code as part of the scientific process.
General components of a software management plan:
- Description of the software.
- Repository(ies) and archive(s) in which software will be shared.
- Sharing guidelines.
- Personnel roles and responsibilities.
- Any community-specific information of note.
At a minimum, a software management plan for SMD-funded research should include: - Description of the software expected to be produced from the proposed activities, including types of software to be produced, how the software will be developed, and the addition of new features or updates to existing software. This can include the platforms used for development, project management, and community-based best practices to be included such as documentation, testing, dependencies, and versioning. - The repository(ies) that will be used to archive software arising from the activities and the schedule for making the software publicly available. - Description of software that are subject to relevant laws, regulations, or policies that exclude them from software sharing requirements. - Roles and responsibilities of project personnel who will ensure implementation of the software management plan.
8.7.4 Open Science Plan
The OSDMP should also describe other open processes as part of the plan. This includes the types of publications that are expected to be produced from the activities, including peer reviewed manuscripts, technical reports, conference materials, and books. The plan should also outline the methods expected to be used to make the publications publicly accessible.
This section may also include a description of additional open science activities associated with the project. This may include:
- Holding scientific workshops and meetings openly to enable broad participation.
- Pre-registering research plans in advance of conducting scientific activities.
- Providing project personnel with open science training or enablement (if not described elsewhere in a proposal).
- Implementing practices that support the inclusion of broad, diverse communities in the scientific process as close to the start of research activities as possible (if not described elsewhere in a proposal).
- Integrating open science practices into citizen science activities.
- Contributions to or involvement in open-science communities.
8.7.5 Publications Plan
A plan for publications is a crucial piece of the OSDMP. A publications plan should include the following features:
- Describes how results will be managed, preserved, and released - in other words, how you will communicate your findings.
- Includes plans for conference talks, whitepapers, peer reviews journal articles, books, and other such documents.
- Written in compliance with any rules and regulations within your organization, as well as from your funding source.
- As with the data and software plans, it serves as a foundational framework for your project from start to finish.
8.7.6 Examples of Requirements for Open Science Management Plans
Globally, organizations and agencies are moving towards open science and beginning to require plans as part of funding. Here are just some of them:
USA - NASA - Open Science and Data Management Plan - NSF - Data Management Plan - NIH - Data Management and Sharing Plan - NOAA - Data and Information Sharing Plan (DISP)
GLOBAL INSTITUTES - Australian Research Council - Data Management Plan - EU Open Science Requirements - https://openscience.eu/Open-Science-in-Horizon-Europe - UK Wellcome Trust - (Output Management Plan) - Korea’s National Research Foundation (NRF) - DMP Guideline - Japan Science & Technology Agency (JST) - Open Access to Research Publications and Research Data Management
And remember, open science is nuanced! Although one of the tenants of open science is to share your products, not all products can or should be shared. How you share them may be specified by your organization or funding agency. As you embark on adopting open science for a project, consider if the subject and approach to your project will allow for sharing. Think about the following questions:
- Can the research products be shared?
- Who helped you obtain your data?
- Will they benefit from release?
- Who has responsibility and/authority for what happens with the data?
- Should the research products be shared?
More details on how to write these plans for data, code, and results are in the following modules.
8.8 Lesson 2: Summary
In this lesson, we learned:
- The definition of science tools, common examples, and which part of the scientific workflow they can support.
- The definition and purpose of persistent identifiers. The usefulness of ORCIDs and DOIs in the scientific process.
- Examples of useful and common open science tools such as metadata, documentation, repositories, and pre-registration.
- The steps for writing an open science and data management plan.
8.9 Lesson 2: Knowledge Check
Answer the following questions to test what you have learned so far.
Question
01/03
What can open science tools help with?
- Discovery
- Writing
- Outreach
- All of above
Question
02/03
Complete the statement:
Good, clear Metadata _____.
Select all that apply.
- Improves findability
- Improves accessibility
- Improves interoperability
- Improves reusability
- Is a waste of time
Question
03/03
Which are the components of a Software Management Plan? Select all that apply.
- Description of the software
- Repository(ies) in which software will be archived
- Sharing guidelines
- Personnel roles and responsibilities
- Any community-specific information of note
- Creating a logo